人間は「ブランド」になれるか? — マコノヒーの商標登録に見る、AI時代のアイデンティティ保護の最前線
俳優マシュー・マコノヒーが声の抑揚や身振りを連邦商標として登録した「マコノヒー戦略」を徹底解説。AIディープフェイクによるなりすまし問題に対し、州パブリシティ権の限界を超え、商標法を活用したアイデンティティ保護の最前線、NO FAKES法案など連邦立法の動向、実践的な監視・収益化戦略まで、AI時代の「ブランド化された人間」という新概念の法的・倫理的課題を多角的に分析します。
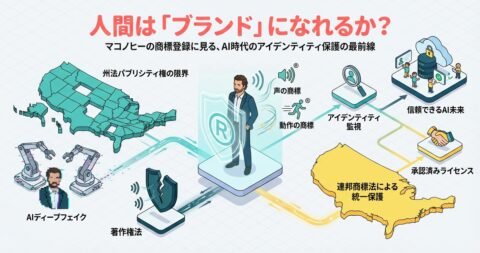
俳優マシュー・マコノヒーが声の抑揚や身振りを連邦商標として登録した「マコノヒー戦略」を徹底解説。AIディープフェイクによるなりすまし問題に対し、州パブリシティ権の限界を超え、商標法を活用したアイデンティティ保護の最前線、NO FAKES法案など連邦立法の動向、実践的な監視・収益化戦略まで、AI時代の「ブランド化された人間」という新概念の法的・倫理的課題を多角的に分析します。

2025年6月、カリフォルニア州北部連邦地方裁判所で下されたKadrey v. Meta Platforms判決は、AI学習における著作権侵害とフェアユース適用の新基準を示した画期的判例です。Richard Kadrey氏ら13名の著名作家がMeta社のLlama AI開発を訴えた本件で、Chhabria判事はMeta社の勝訴を認めましたが、同時に「この判決はMeta社の行為が適法であることを保証するものではない」と明言し、判決の限定的性質を強調しました。特に注目すべきは、裁判所がAI学習による「市場希釈」理論を法的に有効と認めながらも、原告の立証不足により今回は適用されなかった点です。*Bartz v. Anthropic*判決との法的整合性の欠如も相まって、AI開発企業は依然として高度な法的不確実性に直面しており、シャドウライブラリ利用の即座停止、適法な学習データ取得、出力制御機能の強化など、包括的なリスク管理戦略の構築が急務となっています。本記事では、判決の詳細な分析から控訴審での展望まで、AI開発企業が知るべき実務的対応策を徹底解説します。

2025年6月、Disney・Universal等がAI画像生成サービスMidjourneyを著作権侵害で提訴した歴史的事件の核心は、「故意的侵害」の新基準確立にあります。年間3億ドルの収益を上げるMidjourneyが、事前警告を無視し、暴力的コンテンツには実装済みのフィルタリング技術を著作権保護に適用しない「選択的対応」が焦点となっています。Associated PressやNew York Times等が既にAI企業とライセンス契約を締結する中、Midjourneyだけが取り残されている状況と、米国著作権局のライセンシング推奨政策が訴訟の背景にあります。本訴訟は、AI企業への予防的措置義務創設と、最大15万ドル/作品の法定損害金適用により、AI時代の著作権法パラダイムを根本的に変革する可能性があり、知的財産実務に従事する専門家にとって必見の分析となっています。

2025年6月23日、カリフォルニア連邦地裁が下したBartz v. Anthropic判決は、AI学習データの取得方法が著作権侵害の成否を決定する画期的な境界線を示しました。Claude AIを開発するAnthropic社の二つの異なるアプローチ―700万冊を超える海賊版書籍の無断ダウンロードと、数百万冊の合法書籍購入・スキャニング―に対し、裁判所は正反対の法的判断を下しました。同一の最終目的(AI学習)でありながら、海賊版取得については4要素すべてでフェアユースを全面否定し著作権侵害を認定、一方で合法購入による書籍については厳格な条件下で限定的なフェアユースを認定。判決は「便宜性とコスト効率」を理由とした権利侵害は後続の変革的使用でも正当化されず、後発的な合法購入でも先行する盗用の責任は免れないと明確に示し、AI開発企業に対し初期段階からの適切な権利処理の重要性を突きつけました。この地裁判決が確定すれば、AI業界のデータ取得戦略に根本的変化をもたらす可能性があります。

米国著作権局が2025年5月に発表した「生成AI学習」報告書は、AIモデル訓練における著作権問題を詳細に分析しています。この報告書は、AIトレーニングが常にフェアユースに該当するという主張を否定し、ケースバイケースでの評価を強調しています。特に注目すべきは、変形的利用の限界、違法入手コンテンツの使用がフェアユースに不利に働く点、そして市場希薄化の懸念です。報告書は第4要素(市場への影響)を最重要と位置づけ、ライセンスフレームワークの開発を強く推奨しています。本稿では、フェアユース4要素の詳細な分析と、AI開発企業、知的財産権者、法務担当者それぞれへの実務的影響を解説し、特許実務者がクライアントへの助言に活用できる重要ポイントを提供します。

2025年4月18日、CAFCが下したRecentive Analytics v. Fox Corp判決は、機械学習特許に関する画期的な先例を確立しました。CAFCは「既存の機械学習手法を新しいデータ環境に単に適用するだけでは特許適格性がない」と明示し、技術自体の改良に焦点を当てることの重要性を強調しました。本記事では、この重要判決の法的分析から、「任意の適切な機械学習技術」という表現が特許性判断に与えた影響、そして機械学習特許の出願戦略における具体的な技術的改良の明確化や実装詳細の重要性まで詳細に解説します。AI関連発明の特許取得を目指す企業や知財専門家にとって、成功確率を高めるための必須知識となる重要な判例解説です。

2025年3月、米国D.C.巡回控訴裁判所はAI単独で作成された作品は著作権保護の対象外であると判断し、知的財産法における「人間の著作者性」の重要性を確立しました。本稿ではThaler v. Perlmutter事件の詳細分析を通じて、裁判所が著作権法の条文解釈から「著作者」は人間でなければならないと結論づけた法的根拠、AIを「従業員」とみなす「職務著作」の適用が否定された理由、そして特許分野における類似判断との整合性を解説します。さらに、AIと人間の協働による創作物の著作権保護の可能性や、AIを活用する知的財産戦略において実務家が留意すべき点も考察し、進化するAI時代における著作権法の境界線と今後の展望を明らかにします。

スタジオジブリ風のAI生成アートが法的論争の中心となっている今、直面する複雑な知財問題を徹底解説しています。米国著作権法の「アイデア・表現二分法」が芸術的スタイルを保護しない一方で、ランハム法に基づく商標侵害の可能性やパブリシティ権の新たな解釈など、代替的保護手段も検討されています。宮崎駿監督自身がAIアニメーションを「生命そのものへの侮辱」と評した状況下で、OpenAIのポリシーや国際的な法的枠組みの違い、さらには進行中の訴訟が業界に与える影響まで、AI時代の知的財産管理に必要な実践的アドバイスと将来展望を網羅した必読の記事です。

2025年2月、米国デラウェア州連邦地裁はAI開発における著作権侵害とフェアユースの境界を画定する重要判決を下しました。Thomson Reuters v. ROSS Intelligence事件では、法律情報データベース「Westlaw」のヘッドノートをAIトレーニングに使用したことが著作権侵害に当たり、フェアユース防御は適用されないと判断されました。本判決は市場への影響を最重視し、AIトレーニング目的であっても著作物の無許可利用は正当化されないという重要な先例を打ち立てています。特に、「変形的使用」の認定基準や非生成AIと生成AIの法的区別など、今後のAI著作権訴訟に大きな影響を与える論点を含み、知的財産専門家が注目すべき事例となっています。現在も中間上訴中のこの訴訟から、AI開発と著作権保護のバランスについて実務的な示唆を得ることができます。
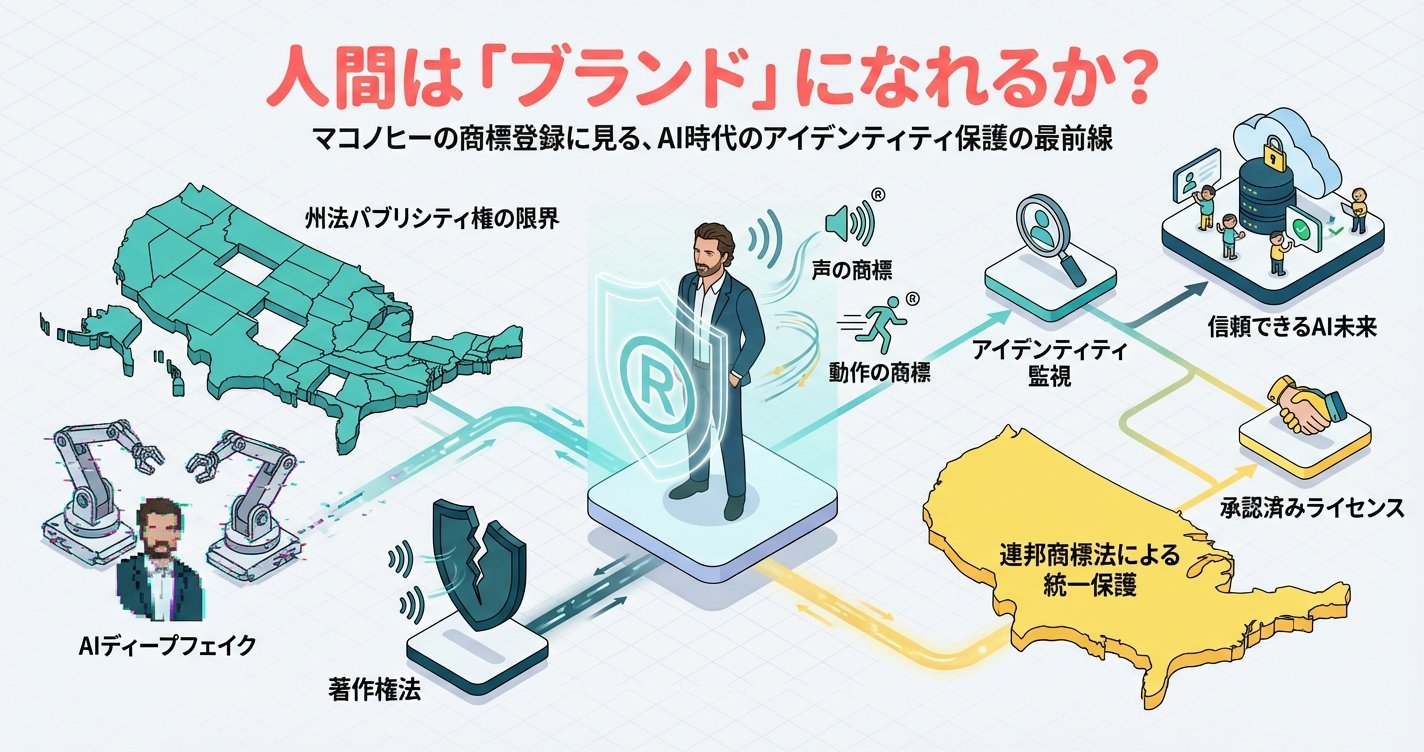
俳優マシュー・マコノヒーが声の抑揚や身振りを連邦商標として登録した「マコノヒー戦略」を徹底解説。AIディープフェイクによるなりすまし問題に対し、州パブリシティ権の限界を超え、商標法を活用したアイデンティティ保護の最前線、NO FAKES法案など連邦立法の動向、実践的な監視・収益化戦略まで、AI時代の「ブランド化された人間」という新概念の法的・倫理的課題を多角的に分析します。

2025年6月、カリフォルニア州北部連邦地方裁判所で下されたKadrey v. Meta Platforms判決は、AI学習における著作権侵害とフェアユース適用の新基準を示した画期的判例です。Richard Kadrey氏ら13名の著名作家がMeta社のLlama AI開発を訴えた本件で、Chhabria判事はMeta社の勝訴を認めましたが、同時に「この判決はMeta社の行為が適法であることを保証するものではない」と明言し、判決の限定的性質を強調しました。特に注目すべきは、裁判所がAI学習による「市場希釈」理論を法的に有効と認めながらも、原告の立証不足により今回は適用されなかった点です。*Bartz v. Anthropic*判決との法的整合性の欠如も相まって、AI開発企業は依然として高度な法的不確実性に直面しており、シャドウライブラリ利用の即座停止、適法な学習データ取得、出力制御機能の強化など、包括的なリスク管理戦略の構築が急務となっています。本記事では、判決の詳細な分析から控訴審での展望まで、AI開発企業が知るべき実務的対応策を徹底解説します。

2025年6月、Disney・Universal等がAI画像生成サービスMidjourneyを著作権侵害で提訴した歴史的事件の核心は、「故意的侵害」の新基準確立にあります。年間3億ドルの収益を上げるMidjourneyが、事前警告を無視し、暴力的コンテンツには実装済みのフィルタリング技術を著作権保護に適用しない「選択的対応」が焦点となっています。Associated PressやNew York Times等が既にAI企業とライセンス契約を締結する中、Midjourneyだけが取り残されている状況と、米国著作権局のライセンシング推奨政策が訴訟の背景にあります。本訴訟は、AI企業への予防的措置義務創設と、最大15万ドル/作品の法定損害金適用により、AI時代の著作権法パラダイムを根本的に変革する可能性があり、知的財産実務に従事する専門家にとって必見の分析となっています。

2025年6月23日、カリフォルニア連邦地裁が下したBartz v. Anthropic判決は、AI学習データの取得方法が著作権侵害の成否を決定する画期的な境界線を示しました。Claude AIを開発するAnthropic社の二つの異なるアプローチ―700万冊を超える海賊版書籍の無断ダウンロードと、数百万冊の合法書籍購入・スキャニング―に対し、裁判所は正反対の法的判断を下しました。同一の最終目的(AI学習)でありながら、海賊版取得については4要素すべてでフェアユースを全面否定し著作権侵害を認定、一方で合法購入による書籍については厳格な条件下で限定的なフェアユースを認定。判決は「便宜性とコスト効率」を理由とした権利侵害は後続の変革的使用でも正当化されず、後発的な合法購入でも先行する盗用の責任は免れないと明確に示し、AI開発企業に対し初期段階からの適切な権利処理の重要性を突きつけました。この地裁判決が確定すれば、AI業界のデータ取得戦略に根本的変化をもたらす可能性があります。

米国著作権局が2025年5月に発表した「生成AI学習」報告書は、AIモデル訓練における著作権問題を詳細に分析しています。この報告書は、AIトレーニングが常にフェアユースに該当するという主張を否定し、ケースバイケースでの評価を強調しています。特に注目すべきは、変形的利用の限界、違法入手コンテンツの使用がフェアユースに不利に働く点、そして市場希薄化の懸念です。報告書は第4要素(市場への影響)を最重要と位置づけ、ライセンスフレームワークの開発を強く推奨しています。本稿では、フェアユース4要素の詳細な分析と、AI開発企業、知的財産権者、法務担当者それぞれへの実務的影響を解説し、特許実務者がクライアントへの助言に活用できる重要ポイントを提供します。

2025年4月18日、CAFCが下したRecentive Analytics v. Fox Corp判決は、機械学習特許に関する画期的な先例を確立しました。CAFCは「既存の機械学習手法を新しいデータ環境に単に適用するだけでは特許適格性がない」と明示し、技術自体の改良に焦点を当てることの重要性を強調しました。本記事では、この重要判決の法的分析から、「任意の適切な機械学習技術」という表現が特許性判断に与えた影響、そして機械学習特許の出願戦略における具体的な技術的改良の明確化や実装詳細の重要性まで詳細に解説します。AI関連発明の特許取得を目指す企業や知財専門家にとって、成功確率を高めるための必須知識となる重要な判例解説です。

2025年3月、米国D.C.巡回控訴裁判所はAI単独で作成された作品は著作権保護の対象外であると判断し、知的財産法における「人間の著作者性」の重要性を確立しました。本稿ではThaler v. Perlmutter事件の詳細分析を通じて、裁判所が著作権法の条文解釈から「著作者」は人間でなければならないと結論づけた法的根拠、AIを「従業員」とみなす「職務著作」の適用が否定された理由、そして特許分野における類似判断との整合性を解説します。さらに、AIと人間の協働による創作物の著作権保護の可能性や、AIを活用する知的財産戦略において実務家が留意すべき点も考察し、進化するAI時代における著作権法の境界線と今後の展望を明らかにします。

スタジオジブリ風のAI生成アートが法的論争の中心となっている今、直面する複雑な知財問題を徹底解説しています。米国著作権法の「アイデア・表現二分法」が芸術的スタイルを保護しない一方で、ランハム法に基づく商標侵害の可能性やパブリシティ権の新たな解釈など、代替的保護手段も検討されています。宮崎駿監督自身がAIアニメーションを「生命そのものへの侮辱」と評した状況下で、OpenAIのポリシーや国際的な法的枠組みの違い、さらには進行中の訴訟が業界に与える影響まで、AI時代の知的財産管理に必要な実践的アドバイスと将来展望を網羅した必読の記事です。

2025年2月、米国デラウェア州連邦地裁はAI開発における著作権侵害とフェアユースの境界を画定する重要判決を下しました。Thomson Reuters v. ROSS Intelligence事件では、法律情報データベース「Westlaw」のヘッドノートをAIトレーニングに使用したことが著作権侵害に当たり、フェアユース防御は適用されないと判断されました。本判決は市場への影響を最重視し、AIトレーニング目的であっても著作物の無許可利用は正当化されないという重要な先例を打ち立てています。特に、「変形的使用」の認定基準や非生成AIと生成AIの法的区別など、今後のAI著作権訴訟に大きな影響を与える論点を含み、知的財産専門家が注目すべき事例となっています。現在も中間上訴中のこの訴訟から、AI開発と著作権保護のバランスについて実務的な示唆を得ることができます。